




Tilaa blogimme
Viimeisimmät julkaisut





Scheduling data science workflows in Azure with Argo and Metaflow
In a recent project, we developed a solution with a number of IoT sensors that record chunks of data in an event driven manner. The data of each sensor arrives irregularly as a large time series. We pull the data to Azure Blob Storage, from where they are processed further.
To analyse this data, given the large and growing dataset, the following features were important:
Develop algorithms locally, iterate quickly, track the experiments
Use the cloud to scale up the compute power and run more complex analyses with more data
Deploy the algorithms to the cloud, run them on schedule or from triggers, and monitor them
Let’s be honest, these are generally important properties when working with data :)
The software we like to use to meet these needs is Metaflow, an open source tool for orchestrating the data tool chain. While there are multiple reasons to use Metaflow for data science work, in this blog we’ll focus on the last point of the list above: running flows (your data processing code) in the cloud on schedule or based on triggers. Azure does offer multiple services for executing tasks with schedules and triggers, whether it’s training machine learning models or running extract-transform-load pipelines, but the following way is the most data scientist-friendly we’ve found.
With Metaflow, it’s possible to run workflows in the Azure cloud using Azure Kubernetes Service (AKS), from the convenience of your laptop and your favourite editor. Basically, you develop the data processing and analysis locally, and flip a switch (literally, --with kubernetes) to run your code in your cloud cluster instead of your local machine. The ease of scaling this gives you cannot be understated.
For scheduling flows, the tech of choice here is going to be Argo Workflows, an open-source workflow orchestrator for Kubernetes (not to be confused with other Argo projects, like Argo CD or Argo Events!). Metaflow allows you to deploy your code as Argo Workflows… workflows 🙃. This gives you multiple benefits. First, your code no longer requires your computer to be run, allowing complete automation. Second, you can choose to run your code on a fixed schedule or based on events and triggers. For example, in Azure you can set up a serverless function to monitor your databases or blob storage, and trigger flows in response to events. Third, you get usual workflow manager goodies like retries, monitoring and notifications. Finally, you can leverage your existing Kubernetes environment!
You can deploy the necessary cloud infrastructure using Terraform templates provided by Outerbounds, the company behind Metaflow. This will install all resources, including AKS and Argo Workflows. We’ve also covered the setup here. The one addition to make, if you previously were not using Argo with Metaflow, is to read the post-deployment instructions (terraform show) again, and verify you have METAFLOW_KUBERNETES_NAMESPACE=argo in your Metaflow configuration file (~/.metaflowconfig/config.json). With the infrastructure in place, you get neat UIs for Metaflow and Argo, so that you can follow your flow deployments and executions graphically. Now, let’s deploy some flows to the cloud!
Argo Workflows in Azure
Let’s now see an example of working with Argo Workflows and Metaflow. We’ll write a flow, make sure it runs in Kubernetes, and finally we’ll schedule the flow with Argo.
When we run flows with Kubernetes, with or without Argo, we need to make sure that all dependencies of our program are available. Metaflow takes care of sending our local python files. To install third-party libraries, Metaflow supports Conda environments. This is basically the only difference between running flows locally, where we’ll typically have everything installed in our Python virtual environment, and running flows in the cloud where we need a mechanism for downloading dependencies. Especially true with Kubernetes, where pods executing our code are ephemeral by design. Pods come and go, and it’s our responsibility to program accordingly.
The following Metaflow flow definition takes care of dependencies and much more. Here’s the code:
"""Flow to analyze sensor data."""
from metaflow import FlowSpec, step, conda_base, schedule
import processing
@conda_base(python="3.10.8", libraries={"numpy": "1.23.5"})
@schedule(cron='0 * * * * *')
class SensorProcessingFlow(FlowSpec):
"""Flow to process raw sensor data."""
@step
def start(self):
self.data = processing.extract()
self.next(self.preprocess)
@step
def preprocess(self):
self.preprocessed = processing.preprocess(self.data)
self.next(self.filter_bank, self.lags)
@step
def filter_bank(self):
self.next(self.join)
@step
def lags(self):
self.next(self.join)
@step
def join(self, inputs):
self.merge_artifacts(inputs)
self.next(self.end)
@step
def end(self):
"""End the flow."""
if __name__ == "__main__":
SensorProcessingFlow()
We import the usual FlowSpec and step from Metaflow, with the additional conda_base and schedule functions. We also import a local file called processing, which contains functions for data extraction and uses Numpy to process our data.
We then define our SensorProcessingFlow. The flow starts by fetching data, does initial processing, then branches into parallel feature extraction steps. I’ve omitted details of the steps here. You’ll soon see how these steps map to Argo workflow templates!
Notice the decorators of the flow, @conda_base and @schedule. With the conda_base decorator, we tell Metaflow what to install in order to successfully run this flow. If you don’t specify a Python version, your local version will be inferred. Handy, but not explicit! It’s good practice to set the Python version along with the libraries.
It’s possible to define environments per step as well. This may be more efficient if your flow has dependencies on only a small number of steps. I find the flow-level environment cleaner whenever the flow allows it and there’s no need to optimize the runtime of each step. In case you do use step-level environments, remember to also use step-level imports! The code above could be adapted to ..
from metaflow import FlowSpec, step, conda
…
@conda(python="3.10.8", libraries={"numpy": "1.23.5"})
@step
def start(self):
import processing
self.data = processing.extract()
self.preprocessed = processing.preprocess(self.data)
self.next(self.filter_bank, self.lags)..if only this step uses the processing-module.
When you run this flow, Metaflow UI will show the graphical representation of the execution graph:

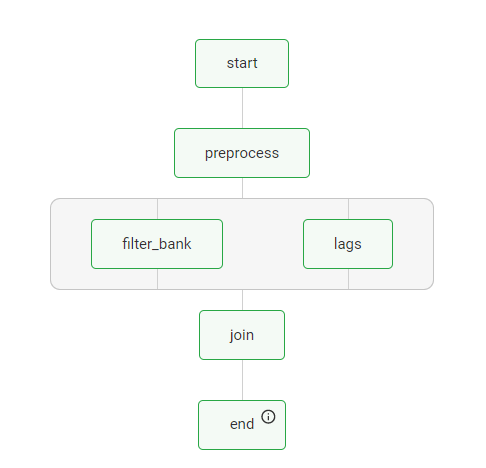
That’s cool, but we’re not here to drool over graphical descriptions of directed acyclic graphs today. We want to schedule the flow to run automatically in the cloud! So let’s do that. First, to interact with the Kubernetes cluster running your Metaflow service, you’ll need to forward the necessary ports with Kubectl. The Metaflow-tools repository provides a handy script for that at scripts/forward_metaflow_ports.py. To interact with Argo, we’ll run the script with the following arguments
python forward_metaflow_ports.py --include-argoand that’s it. Your Metaflow artifacts will contain all data from local flows as well as cloud flows! By default, you can now find the Argo UI at https://localhost:2746. But there won’t be much to see yet. Now, we’ll deploy our flow to Argo as a template:
python sensor_processing_flow.py --environment=conda argo-workflows createIf you now go to the Argo UI, the “Workflow Templates” section should now have content:


Success! You can now tell Argo to trigger your flow to run:
python sensor_processing_flow.py --environment=conda argo-workflows triggerAnd the flow will be run in Kubernetes, completely independent of your local machine. You can find live status of the flow as well as all logs on the Argo UI as well! Moreover, Argo offers many ways to trigger flows, in later blogs we’ll cover using sensors and event sources for this purpose.
Now for the scheduling part. Good news! Recall the decorators of our flow, one of them was @schedule. With this decorator, argo-workflows create will also schedule our flow to run automatically at the set times! It’s possible to leave out this decorator from the flow and do the scheduling using Argo configuration YAML files, for example through the Argo UI, but Metaflow offers this efficient method. The schedule-function supports shorthands such as “hourly”, but you can give any cron pattern as well, like I did in the example above. So time to put that crontab.guru into use :) On the “Cron Workflows” tab of the Argo UI, you should now see a flow that is scheduled to run in the near future:


When using Argo to schedule flows, both the Argo and Metaflow will keep track of flow runs. You can use either UI to quickly check the status or logs of the flows. On Argo Workflows, currently running flows can be explored in real time! Past flows on the Argo UI will only show those triggered by Argo:


whereas the Metaflow UI will also show those run and triggered locally (see the User column):


That’s the basics for scheduling your flows! Let's recap what we did:
Define our data processing flow as a Metaflow flow
Deploy the Metaflow cloud infrastructure, including Azure Kubernetes Service, using Terraform
Wrap the code in
@condadecorators so that it can be run in Kubernetes with our dependenciesUse the
@scheduledecorator to instruct Argo Workflows to run this flow at specific times
This is a very powerful method to get from local prototyping to an automated setup.
If topics like these interest you, read more about our free data science infrastructure meetups at https://softlandia.fi/en/blog/data-science-infrastructure-event and sign-up for our upcoming free event at https://www.eventbrite.com/e/data-science-infrastructure-meetup-12023-onsite-tickets-493714582607!
Don't hesitate to reach out if you'd like to discuss with us: